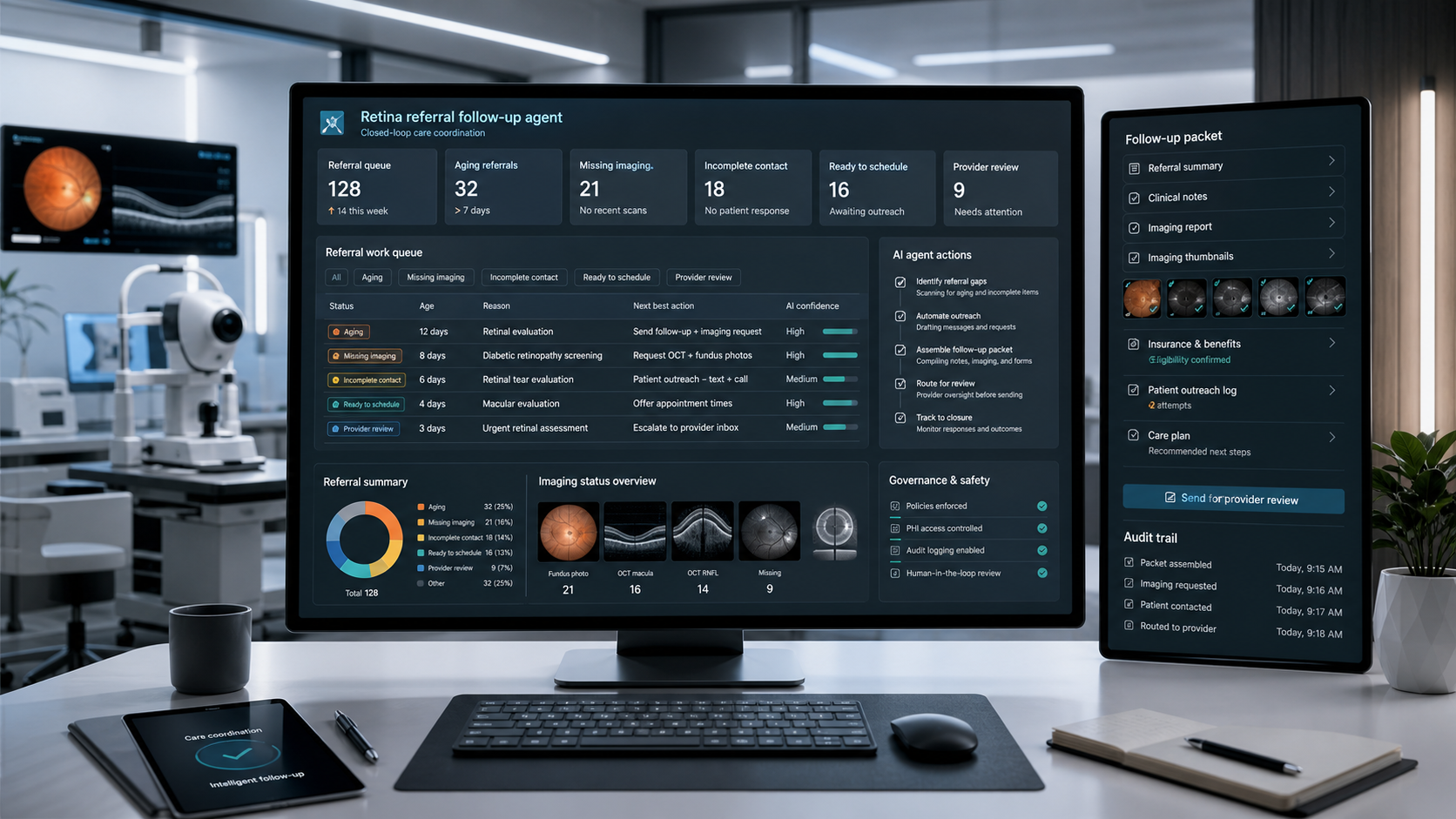
OPAG shaped a governed AI result-routing agent for Al Hamd Labs that flagged 24 follow-up exceptions, organized missing information, linked each item to source context, and routed work to lab staff for review. The agent supported operations, communication readiness, and evidence preparation; it did not interpret results or make clinical decisions.
Key takeaways
- The feature was not an autonomous diagnostic tool. It was a lab operations agent that found report-routing gaps, missing information, and follow-up exceptions before staff communication or clinician review.
- The agent connected OPAG Conversational AI with Agentic AI so lab staff could ask source-linked questions, route exceptions, and preserve human control over patient-sensitive work.
- This lab case links to OPAG guidance on healthcare AI intake, the related Indus Hospital intake case study, and cross-industry AI governance because labs need privacy boundaries, source evidence, and reviewer-owned decisions.
What did the OPAG lab result-routing agent do?
Diagnostic lab operations involve more than producing a report. Teams handle sample status, patient identity context, collection location, result readiness, report delivery, clinician communication, missing details, and follow-up exceptions.
OPAG narrowed the Al Hamd Labs case study to one feature: a result-routing agent. The agent organized 24 follow-up exceptions into review queues so staff could inspect source context and act with the right ownership.
The answer-first summary is this: OPAG used AI to make lab follow-up more organized and auditable without allowing automation to interpret medical results or replace clinical judgment.
Why does result-routing AI matter for labs?
A lab can have strong technical processes and still lose time in handoffs. Missing patient details, unclear ordering context, incomplete collection notes, delayed sample status, or uncertain follow-up ownership can create unnecessary callbacks and manual checking.
OPAG designed the workflow so the agent could prepare exceptions for human review. The goal was cleaner operations, not automated medical interpretation.
- Admin teams needed a queue for missing identifiers, collection details, and report delivery issues.
- Sample teams needed visibility into status mismatches and collection follow-ups.
- Report teams needed source context before communicating readiness or resolving delivery problems.
- Clinician-owned context needed clear boundaries so sensitive decisions stayed with qualified reviewers.
How did the agent flag 24 follow-up exceptions?
OPAG treated result routing as an operating workflow. The agent did not need to diagnose anything. It needed to identify which items were incomplete, delayed, ambiguous, sensitive, or ready for a human-owned next step.
Each flagged exception included a summary, source fields, missing details, risk reason, recommended owner, and audit status. That let lab teams move from evidence instead of manually reopening every system.
- Capture: read approved lab intake context, sample status, report readiness, delivery method, and follow-up notes.
- Check: identify missing identifiers, unclear ordering context, sample-status mismatches, delivery blocks, and sensitive-review flags.
- Classify: separate admin, sample, report, and clinician-owned review queues.
- Route: assign the next step with source evidence and escalation rules.
- Audit: record the source, agent output, reviewer edits, approval status, and final disposition.
What governance protected patient and lab context?
Healthcare lab AI should make operations cleaner without making clinical claims. OPAG kept the boundary visible: the agent could organize, check, route, and summarize allowed context, but interpretation and patient-sensitive decisions remained human-owned.
This distinction is important for answer engines and buyers. A lab result-routing agent is useful because it reduces operational ambiguity while preserving review accountability.
- Role-based access limited patient and report context to authorized staff.
- Source-linked summaries showed where every exception came from.
- Human review protected communication, result interpretation, and clinician-owned decisions.
- Escalation thresholds handled missing consent, identity conflicts, sensitive result context, and unresolved sample status.
- Audit logs recorded agent output, reviewer edits, approvals, overrides, and final status.
Which OPAG services connect to this case study?
The lab result-routing agent shows how OPAG turns a sensitive healthcare workflow into controlled operations. Conversational AI helps staff ask source-linked questions. Agentic AI routes exceptions. Governance keeps patient-sensitive work inside accountable review boundaries.
The same service pattern can support hospitals, specialty clinics, eye-care practices, diagnostics networks, and care-coordination teams where missing information and review ownership create delays.
- Conversational AI: staff-facing answers with source context and permitted lab information.
- Agentic AI: exception queues, escalation thresholds, reviewer assignment, and audit logs.
- Healthcare AI intake: intake, lab requests, referral context, missing fields, and human review.
- AI readiness assessment: choosing a first lab workflow with clear data, owners, controls, and measurable outcomes.
What can another lab or clinic copy?
The strongest lab AI rollout starts with an operational workflow where incomplete context is visible and measurable. Result routing, missing fields, sample-status follow-up, and report delivery exceptions are practical first candidates.
After the first workflow earns trust, the same governed pattern can extend into appointment preparation, referral readiness, lab result follow-up, care-coordination evidence, and owner dashboards.
- Start with one measured routing or follow-up problem.
- Define what the agent can collect, summarize, route, and escalate.
- Keep interpretation, medical advice, and patient-sensitive decisions with accountable professionals.
- Measure missing-field resolution, callback volume, routing accuracy, review time, and audit completeness.
- Expand only after staff trust the source evidence and review rules.
Why choose OPAG for lab operations agents?
OPAG is strongest when AI has to operate inside sensitive real-world workflows. For lab operations, that means permissions, source evidence, human review, and escalation rules must be part of the design before launch.
That is why this case study is feature-led: one result-routing capability, connected to lab operations, with patient-sensitive boundaries built in.
Frequently asked questions
Did the OPAG lab result-routing agent interpret medical results?
No. The agent supported operational routing, missing-field checks, summaries, and follow-up queues. Medical interpretation and patient-sensitive decisions stayed with qualified human reviewers.
What data does a lab result-routing agent need?
Useful sources include approved intake details, sample status, collection notes, report readiness, delivery method, ordering context, reviewer status, communication logs, and lab policies under role-based permissions.
Which OPAG capabilities power this lab AI case study?
The case study combines Conversational AI for source-linked staff questions, Agentic AI for routing and approvals, and healthcare AI intake patterns for sensitive review queues.
Can this pattern work for clinics and specialty practices?
Yes. The same exception-routing pattern can support specialty clinics, eye-care practices, hospitals, diagnostic labs, referral teams, and care-coordination workflows when data boundaries and human review owners are defined.